
Texas TI99 from 1979
UPDATE: Stewart, in the comments, makes an excellent point:
“There is a great analogy with the development of hydrological models in the 1960′s (because we could automate computation) – in 2013, we are still unable to simulate process accurately – it doesn’t stop us from building the models with increasing complexity which many then blindly believe however the programmer has decided to represent individual processes…“
In 1979, personal computers looked like this.
In 2013, you carry around a supercomputer in your pocket (a smartphone), with the processing power of a warehouse full of TI 99s, and millions of times the 16k storage capacity.
Such is the speed of progress in computer technology. How has climate science fared by comparison?
In climate, the only number that really matters is the sensitivity of the climate to a doubling of CO2. Normally, over a period of years, greater understanding, better modelling and greater computing power will reduce the margins of error as the theories become more finely tuned.
So how has the IPCC done, after 34 years and billions of taxpayer dollars? The following plot shows the range of climate sensitivity since the Charney Report of 1979, and then through the IPCC’s FAR, SAR, TAR, AR4 and AR5:
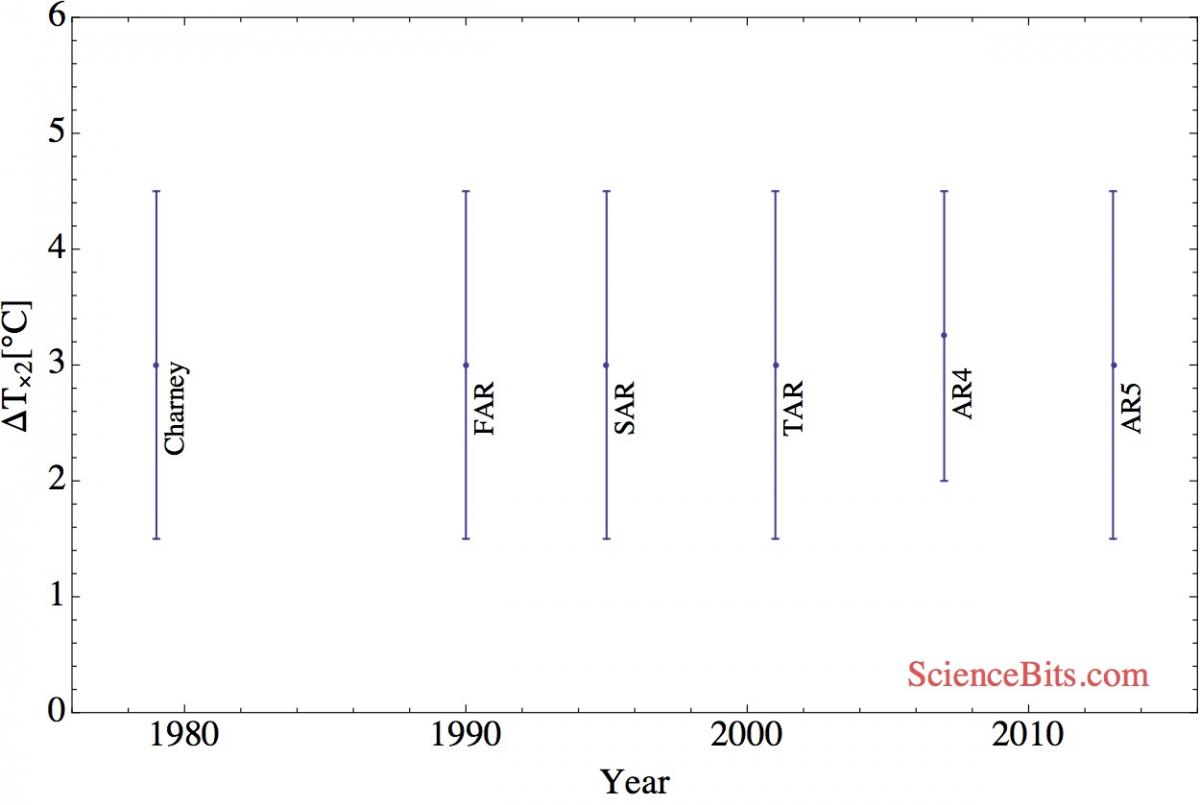
Epic fail
As as you can see, despite a slight narrowing of the range in AR4, the precision of the sensitivity value hasn’t improved at all from 1979 to today. Not one bit. Nada. Zip. Zilch. Zero. Despite billions of dollars of taxpayers’ hard earned cash, thousands of scientists and years of research, the entire climate science community has failed to improve on the original estimate for climate sensitivity made 34 years ago.
Prof Nir Shaviv writes:
if the basic premises of a theory are wrong, then there is no improved agreement as more data is collected. In fact, it is usually the opposite that takes place, the disagreement increases. In other words, the above behavior reflects the fact that the IPCC and alike are captives of a wrong conception.
Full story here.
(h/t Lubos)

According to the Charney Report of 1979, “Unfortunately, only gross globally and zonally averaged features of the present climate can now be reasonably well simulated. At present we cannot simulate accurately the details of regional climate and thus cannot predict the locations and intensities of regional climate changes with confidence. This situation may be expected to improve gradually as scientific understanding is acquired and faster computers are built.“
More scientific understanding has been acquired and faster computers have been built … but as far as climate modeling is concerned, we’re still stuck in the 70’s!
They are in a bind, because if they update their original estimates too much they admit error when they said before they were very sure, (and because the information is public they cant alter the past or just push it under the carpet). And if they don’t change their original estimates, they can be accused of being rigid and unable to make improvements or change. Funny thing politics, you can’t please all the people all the time.
They only thing they can improve and change therefore, is the certainty, which becomes laughable in the case where the data starts pointing in the other direction, which is what is now happening. Same problem with all politically based bureaucracies, they made this a problem when they conveniently decided that that were far more sure about things then they should have been-now they can’t go back on it now without looking foolish. Normally political movements caught in such a bind try to bury and alter the past, but in the information age, this is virtually impossible.
If the temperatures refuse to follow the party line, as nature often does, and they eventually have to reduce the estimates below even their own range, then they give the power back to the data, old hardliners retire and get sidelined, and things might then get back to something near normal. The good old days of the revolution when everybody was so sure of themselves will be no more. You can see and expect such a process by looking up any standard history of socialist revolutions.
The great problem is exactly the huge growth in computational power – because we can compute it, we will. Alas, the understanding of climate physics/processes has not matched the computational ability. There is a great analogy with the development of hydrological models in the 1960’s (because we could automate computation) – in 2013, we are still unable to simulate process accurately – it doesn’t stop us from building the models with increasing complexity which many then blindly believe however the programmer has decided to represent individual processes…
.
But wait theres more…..
The madness rolls on.
http://www.canberratimes.com.au/environment/collector-wind-farm-project-recommended-to-go-ahead-20131011-2vcu1.html
A NSW government recommendation for a 63-turbine wind farm to proceed at Collector will be met with strong opposition at a community meeting, according to opponents of the project who say they’ve been “shafted” by the planning process.
Individuals from the community will get five minutes each to address the PAC at the meeting, while organisations will get 15 minutes – but Mr Hodgson said it wasn’t enough time to go through all their objections.
Ah. The TI99 – my first computer, and what a beauty she was, far better then the competition of the day. My brother still has his, complete with many cartridges and we’ve both spent the rest of our lives in IT. Thanks for the memories.